BIOL 1400 -- Lecture Outline 22
"If you go buzzing about between right and wrong, vibrating and fluctuating,
you come out nowhere; but if you are absolutely and thoroughly and persistently
wrong, you must, some of these days, have the extreme good fortune of knocking
your head against a fact, and that sets you all straight again." -- Thomas Henry
Huxley
I. Recap:
- DNA base pairs are arranged in a particular order.
- That order carries meaning -- just as the order of letters in this
sentence carries meaning.
- Specifically, each gene is a stretch of DNA that carries the
instructions that you need to make one protein.
- Here's the DNA base sequence that carries the instructions for making
the protein insulin, which regulates the amount of sugar in your blood.
-
TTGTATTGGGGGTTTTGGCTGTTACTCTGTCTCTCCATCAGGTCATCATCCTTTCATCATG
GCTCTGTGGATGCATCTCCTCACCGTGCTGGCCCTGCTGGCCCTCTGGGGGCCCAACACTA
ATCAGGCCTTTGTCAGCCGGCATCTGTGCGGCTCCAACTTAGTGGAGACATTGTATTCAGT
GTGTCAGGATGATGGCTTCTTCTATATACCCAAGGACCGTCGGGAGCTAGAGGACCCACAG
GGTGAGCCCCTACCTGCCATCCCTGCTGTTTCCGTGCCAGTACCCCAGCTGGCAGGGCATA
AGTAAGCAGGAAGCTAATTCCAAGGAGAGTCGATGGGTTTGTTGAAAAGGGAGGCGGCTCT
CTTGGTCATTTCGTAAAGTGGTGGTGGCTTCCTATAGCTGCTTTTAAGGGTAAAGGGTAAC
AGCTGCACCCTTCAGCTGTGGCTTCTGAGCACAACTGGACTCTTCCCTCCACTTGCCTTCG
AATGACTGCCCTGGCCTCATGGCAACAGTAGCTCCCTGGTACCAATTTTATTATGCAGATT
GCATCTTGGTGTTGATAGCCTTAGGGTAGCCTGGGGGCCATTCATGGGGCGCCCCATCCCT
CCTTCCTCCCTGCCTCTGGACAAATGCTCCATGGAGCTCCAAGCTCTGCCACGTGGGAGGT
GTGGGTCTCCAGCGCTCTGTGTGCCCAGCATGGCAGCCTCTGTCACCTGGACCAGCTCCCT
GGGAGATGCAGTGAGAGGGTGGTAGTGTGGGGCCAGTGCGCAGGCATTCTGCTGCTCCTGA
CAGCATCTGCCCCTGTCTCTCTCCCCACTGCTGCTGCTCCTGTATTCTGGCACCTCACCCT
GCAGTGGAGCAGACAGAACTGGGCATGGGCCTGGGGGCAGGTGGACTACAGCCCTTGGCAC
TGGAGATGGCACTACAGAAGCGTGGCATTGTGGATCAGTGCTGTACTGGCACCTGCACACG
CCACCAGCTGCAGAGCTACTGCAACTAGACACCTGCCTTGAACCTGGCCTCCCACTCTCCC
CTGGCAACCAATAAACCCCTTGAATGAGCCCCATTGAATGGTCTGTGTGTCATGGAGGGGG
AGGGGCTGACTCAAGGGGGCACATGCATGCCAGCCTATCATCCAGGTTCATTGCAAGACCC
CCTCTCTATGCTCTGTGCACCTCTAACACACCC
Whew!
II. But how do you get from DNA to protein?
- See, here's the problem:
- DNA (in eukaryotes, anyway) is never found outside the nucleus.
- Yet proteins were known to be made in the cytoplasm, not in
the nucleus.
- Francis Crick came up with what he called the "adaptor hypothesis":
There must be some molecule that acts as a "go-between", or "adaptor",
between the DNA and the protein sequence.
- We now know that the "adaptor" is a molecule of the other
important nucleic acid -- RNA.
- RNA is similar to DNA, but differs from DNA in several ways:
- it's usually single-stranded and doesn't form a double helix
- the sugar in its nucleotides is ribose, not deoxyribose
- instead of using the base thymine, it uses a different base called uracil
(abbreviated U.)
- You can see the differences in these formulas:
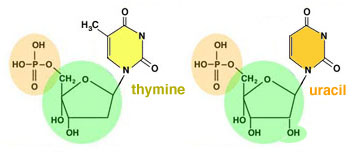
Left: deoxyribose bonded to thymine. Right: ribose bonded to uracil.
- The Central Dogma of Molecular Biology is this: Information
is copied and transmitted in only one direction:
DNA -> RNA -> protein
(There are exceptions to the rule, but for now, understanding the Central Dogma
will work. . . )
III. Transcription
- Transcription is the first step in the Central Dogma scheme: Information
is copied from DNA to RNA
.
- A DNA sequence is used as a pattern to make a single strand of RNA
which is complementary to it.
- Here we have two strands of DNA that would form one double helix:
- ATGGCTCTGTGGATGCATCTCCTCACCGTG -- complementary strand
- TACCGAGACACCTACGTAGAGGAGTGGCAC -- template strand
- Enzymes unzip the helix. Then the enzyme RNA polymerase make
an RNA strand that is complementary to the template strand:
-
AUGGCUCUGUGGAUGCAUCUCCUCACCGUG -- messenger RNA strand
- TACCGAGACACCTACGTAGAGGAGTGGCAC -- template strand
- This RNA -- called messenger RNA -- peels off the DNA. Here's
the messenger RNA, or mRNA, for insulin. . .
-
UUGUAUUGGGGGUUUUGGCUGUUACUCUGUCUCUCCAUCAGGUCAUCAUCCUUUCAUCAUG
GCUCUGUGGAUGCAUCUCCUCACCGUGCUGGCCCUGCUGGCCCUCUGGGGGCCCAACACUA
AUCAGGCCUUUGUCAGCCGGCAUCUGUGCGGCUCCAACUUAGUGGAGACAUUGUAUUCAGU
GUGUCAGGAUGAUGGCUUCUUCUAUAUACCCAAGGACCGUCGGGAGCUAGAGGACCCACAG
GGUGAGCCCCUACCUGCCAUCCCUGCUGUUUCCGUGCCAGUACCCCAGCUGGCAGGGCAUA
AGUAAGCAGGAAGCUAAUUCCAAGGAGAGUCGAUGGGUUUGUUGAAAAGGGAGGCGGCUCU
CUUGGUCAUUUCGUAAAGUGGUGGUGGCUUCCUAUAGCUGCUUUUAAGGGUAAAGGGUAAC
AGCUGCACCCUUCAGCUGUGGCUUCUGAGCACAACUGGACUCUUCCCUCCACUUGCCUUCG
AAUGACUGCCCUGGCCUCAUGGCAACAGUAGCUCCCUGGUACCAAUUUUAUUAUGCAGAUU
GCAUCUUGGUGUUGAUAGCCUUAGGGUAGCCUGGGGGCCAUUCAUGGGGCGCCCCAUCCCU
CCUUCCUCCCUGCCUCUGGACAAAUGCUCCAUGGAGCUCCAAGCUCUGCCACGUGGGAGGU
GUGGGUCUCCAGCGCUCUGUGUGCCCAGCAUGGCAGCCUCUGUCACCUGGACCAGCUCCCU
GGGAGAUGCAGUGAGAGGGUGGUAGUGUGGGGCCAGUGCGCAGGCAUUCUGCUGCUCCUGA
CAGCAUCUGCCCCUGUCUCUCUCCCCACUGCUGCUGCUCCUGUAUUCUGGCACCUCACCCU
GCAGUGGAGCAGACAGAACUGGGCAUGGGCCUGGGGGCAGGUGGACUACAGCCCUUGGCAC
UGGAGAUGGCACUACAGAAGCGUGGCAUUGUGGAUCAGUGCUGUACUGGCACCUGCACACG
CCACCAGCUGCAGAGCUACUGCAACUAGACACCUGCCUUGAACCUGGCCUCCCACUCUCCC
CUGGCAACCAAUAAACCCCUUGAAUGAGCCCCAUUGAAUGGUCUGUGUGUCAUGGAGGGGG
AGGGGCUGACUCAAGGGGGCACAUGCAUGCCAGCCUAUCAUCCAGGUUCAUUGCAAGACCC
CCUCUCUAUGCUCUGUGCACCUCUAACACACCC
IV. Translation
- The messenger RNA goes out to a specialized organelle in the
cytoplasm called a ribosome. It's the ribosome that "reads" the
messenger RNA and translates it into a sequence of amino acids.
- But how are you supposed to read this?
- Remember that there are 20 amino acids that are used in proteins, but
there are only four nucleotide bases. . .
- Francis Crick, and his colleague Sydney Brenner, hypothesized that each amino
acid was coded for by a triplet codon of three bases on one of the strands
(the sense strand) of the DNA double helix.
- One particular triplet happens to be the "start" codon: it's AUG.
AUG also codes for an amino acid, methionine.
Here it is:
-
UUGUAUUGGGGGUUUUGGCUGUUACUCUGUCUCUCCAUCAGGUCAUCAUCCUUUCAUCAUG
GCUCUGUGGAUGCAUCUCCUCACCGUGCUGGCCCUGCUGGCCCUCUGGGGGCCCAACACUA
AUCAGGCCUUUGUCAGCCGGCAUCUGUGCGGCUCCAACUUAGUGGAGACAUUGUAUUCAGU
GUGUCAGGAUGAUGGCUUCUUCUAUAUACCCAAGGACCGUCGGGAGCUAGAGGACCCACAG
GGUGAGCCCCUACCUGCCAUCCCUGCUGUUUCCGUGCCAGUACCCCAGC. . .
- The next three bases read GCU, which codes for the amino acid alanine.
- The next three bases read CUG, which codes for the amino acid leucine.
- The next three bases read UGG, which codes for the amino acid tryptophan. . .
- Get the idea? A cell can read this string of DNA bases:
-
. . .
AUGGCUCUGUGGAUGCAUCUCCUCACCGUG . . . .
and get this string of amino acids, the primary structure of insulin:
-
methionine -
alanine -
leucine -
tryptophan -
methionine -
histidine -
leucine -
leucine -
serine -
valine - . . .
- Notice that the code is redundant -- one amino acid may be coded by
several triplets. (There are sixty-four possible triplet codons and only twenty
amino acids, so this is bound to happen.) For instance, in the example above, both
CUG and CUC
code for the amino acid leucine. (So do the
codons CUU, CUC,
UUA, and UUC,
by the way.)
- Finally, three DNA codons don't code for any amino acid, but instead mean
"stop stringing amino acids together." (These three stop codons are
UAA, UAG, and UGA.)
V. How's translation happen?
- Again: translation happens on ribosomes. . .
- . . . with the help of other types of RNA molecules called transfer RNAs.
- There are sixty-four different types of transfer RNA molecule. They're all single-
stranded, but the strand loops back on itself at several points.
- Each tRNA molecule has one loop (called the anticodon loop), that has
three bases that stick out. These can form hydrogen bonds with a complementary
mRNA codon.
- Each tRNA molecule is also bound to one and only one amino acid. Here's what
they look like:
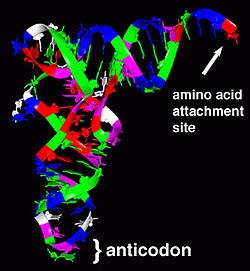
A typical tRNA molecule. For clarity, the sugar-phosphate 'backbone'
is shown as a long ribbon.
- When the mRNA is bound to the ribosome, a tRNA comes along.
- If the tRNA doesn't have bases on the anticodon loop that are complementary
with the first three mRNA base pairs, the tRNA falls back out of the ribosome, and
another tRNA slots in.
- If the tRNA happens to be complementary to the mRNA,
then the tRNA bonds to both the mRNA and the ribosome.
- The ribosome then 'ratchets" down the mRNA by three nucleotides.
- Another tRNA molecule pairs with the next mRNA codon.
- Then a peptide bond is formed between the amino acids carried on the
first and second tRNA molecules. . .
- . . . . and the first tRNA molecule drops off.
- Then the ribosome 'ratchets' down three more nucleotides. . .
- . . . and the process repeats itself. . .
- . . . . until the ribosome hits a 'stop' codon, which -- since this is RNA -- will be either
UAA, UAG, or UGA. Then the ribosome falls apart, and the finished
protein drops away.
- Here's a diagram of the whole process (taken from an old exam of mine).
Try covering up the caption and quizzing yourself:
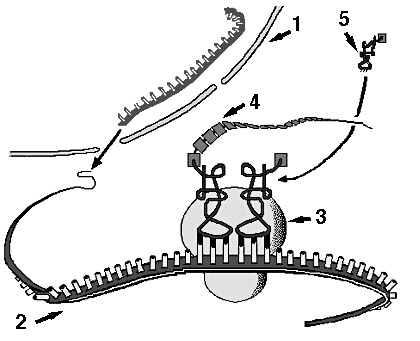
1 -- nuclear membrane
2 -- messenger RNA
3 -- ribosome
4 -- chain of amino acids, soon to fold into a protein
5 -- transfer RNA
Go to Previous Notes |
Return to Lecture Schedule |
Return to Syllabus |
Contact the Prof |
Go to Next Notes